Back to Blog
Secure-by-Design Perspectives
The Evolution of Cloud Security Toward the Daily Work of Security Teams

, Co-founder & CPO

Before starting Native, I worked at AWS, leading one of its largest security products: AWS Security Hub. A few weeks into the role, I met the CISO of a Fortune 100 company that was spending hundreds of millions of dollars in the cloud (if not more). He told me something I still think about often:
“We love Security Hub. But it doesn’t offer us security, just after-the-fact visibility. Why is AWS allowing the bad things to happen in the first place? How can I make sure they don’t happen?”
At first, I spoke with sister teams internally. Surely this has to be solvable. Cloud providers directly expose identity primitives and other guardrails. And yet, when I looked at what it would take to guarantee even one “simple” outcome for that customer, the answer was a messy web of partial technical capabilities and policies, plus a lot of manual stitching.
When I came back to the customer with a path forward, the follow-up question was even more direct:
“How were we supposed to know any of this? And how do we do it not just once, but for our entire cloud security standard? And how do we make it so it takes a day to implement, not a month?”
We met again near the end of my time at AWS. Progress on their side had been minimal, not because they didn’t care, but because the work was manual, deeply technical, and never-ending.
That gap, between the outcomes security teams are accountable for, and the workflows most cloud security tooling is built around, is what ultimately led us to start Native.
How Cloud Security Got Here
If you zoom back to the early 2010s, the first wave of cloud security products made perfect sense.
Cloud adoption was still early. For most companies, cloud was a secondary environment. The crown jewels lived elsewhere, and security teams had plenty of “more urgent” problems.
So the earliest cloud security tools focused on visibility. That model worked when cloud footprints were small and blast radius was limited. Teams saw relatively few findings and could work collaboratively to resolve them quickly.
Fast forward to the late 2010s and early 2020s. Cloud became the primary computing environment for most enterprises. Teams built more in the cloud, more quickly, across more accounts and services. The industry evolved alongside it: CSPM, then CWPP and CIEM, and eventually CNAPP. But the core security motion stayed mostly the same: produce findings, triage, remediate. I’ve seen teams who receive tens of thousands of findings every week. And even when those findings are accurate, they often land at the wrong level of abstraction.
Because what security leaders want to validate is rarely a single checkbox.
If your desired outcome is “production and non-production should never be connected,” that’s not one control. It’s dozens of controls across networking, identity, workloads, and service-specific behavior, multiplied by every account, VPC or VNet, workload type, and exception. The result is a painful reality: locating the few findings that actually matter feels like finding a needle in a haystack, except the haystack keeps growing.
Why “Shift Left” Doesn’t Fully Solve This
When security teams get overwhelmed, the instinct is to push things earlier. Scan the code. Add policy checks to CI. Block unsafe changes.
That works for many classes of problems, and it’s absolutely part of a healthy program. But it struggles with outcome-level guarantees for two reasons.
First, the “production vs. non-production connectivity” example exposes a scale problem. Even if you know every possible path that could connect those environments, it’s not realistic to test every variant in code for every service and every team.
Second, code scanning only covers what flows through a specific pipeline.
What about:
resources created outside the main pipeline, whether in other pipelines or directly in the console,
emergency changes,
teams with different deployment processes,
or connectivity patterns that span multiple applications?
This becomes even harder in multi-cloud environments, where the same intent must be expressed using entirely different primitives.
Trying to guarantee that single outcome with these tools is close to impossible. Outcome-level security is bigger than any single repo or pipeline. So the question becomes: where is the one place you can enforce intent consistently?
Enforcing Intent at the Cloud Control Plane
Cloud security teams have been vocal about the current state: too much noise, too many needles, and too little ability to guarantee what actually matters.
“Secure-by-design” is the response to that. The goal is straightforward: turn single-sentence security outcomes into enforceable guardrails, and make them hard to bypass and safe to roll out.
The only way to achieve this level of certainty is by enforcing guardrails at the source, within the cloud provider itself. Luckily, this is also where cloud providers are investing heavily. I’ve heard countless customers make the same request as that Fortune 100 CISO, and providers have listened. Over the last few years, AWS, Azure, Google Cloud, and OCI have introduced more and more capabilities that allow teams to enforce these outcomes. But there’s a catch.
These capabilities are deeply technical. Security teams can’t simply log into a cloud console, declare “production should never talk to non-production,” and have that intent magically become reality.
Instead, teams have to:
choose the right primitives,
write technical artifacts,
scope them carefully,
preview impact,
orchestrate rollout,
manage exceptions,
detect drift,
and keep everything aligned as cloud usage evolves and providers update their platforms.
In other words, secure-by-design turns cloud security into cloud engineering, and that engineering requires time, resources, and expertise.
How Security Teams Actually Do the Work
One of the most consistent patterns we saw while spending time with cloud security teams is that secure-by-design isn’t a one-time project. It’s a repeating loop.
When security engineers and cloud architects implement guardrails, they move through five steps:
Discover: Identify the security outcome, then map the current cloud environment and existing enforcement controls to understand what already exists, what’s missing, and where the real gap is.
Plan: Define how that outcome should apply in your environment. Scope it to the right environments, services, and business units. Decide what “good” looks like and where exceptions are acceptable, or even necessary.
Simulate: Preview real-world impact before enforcement. This usually means collecting logs and signals to estimate who and what would be affected, so changes can be introduced safely without breaking existing applications.
Implement: Translate the plan into provider-specific technical controls, manage rollout, and coordinate with the teams that will feel the impact. This often needs to be repeated across multiple cloud providers, each with its own model and primitives.
Operationalize: Keep guardrails effective over time. Manage exceptions, watch for drift, adjust as business needs change, and adopt new cloud capabilities as they launch.
This isn’t a linear path, it’s a cycle.
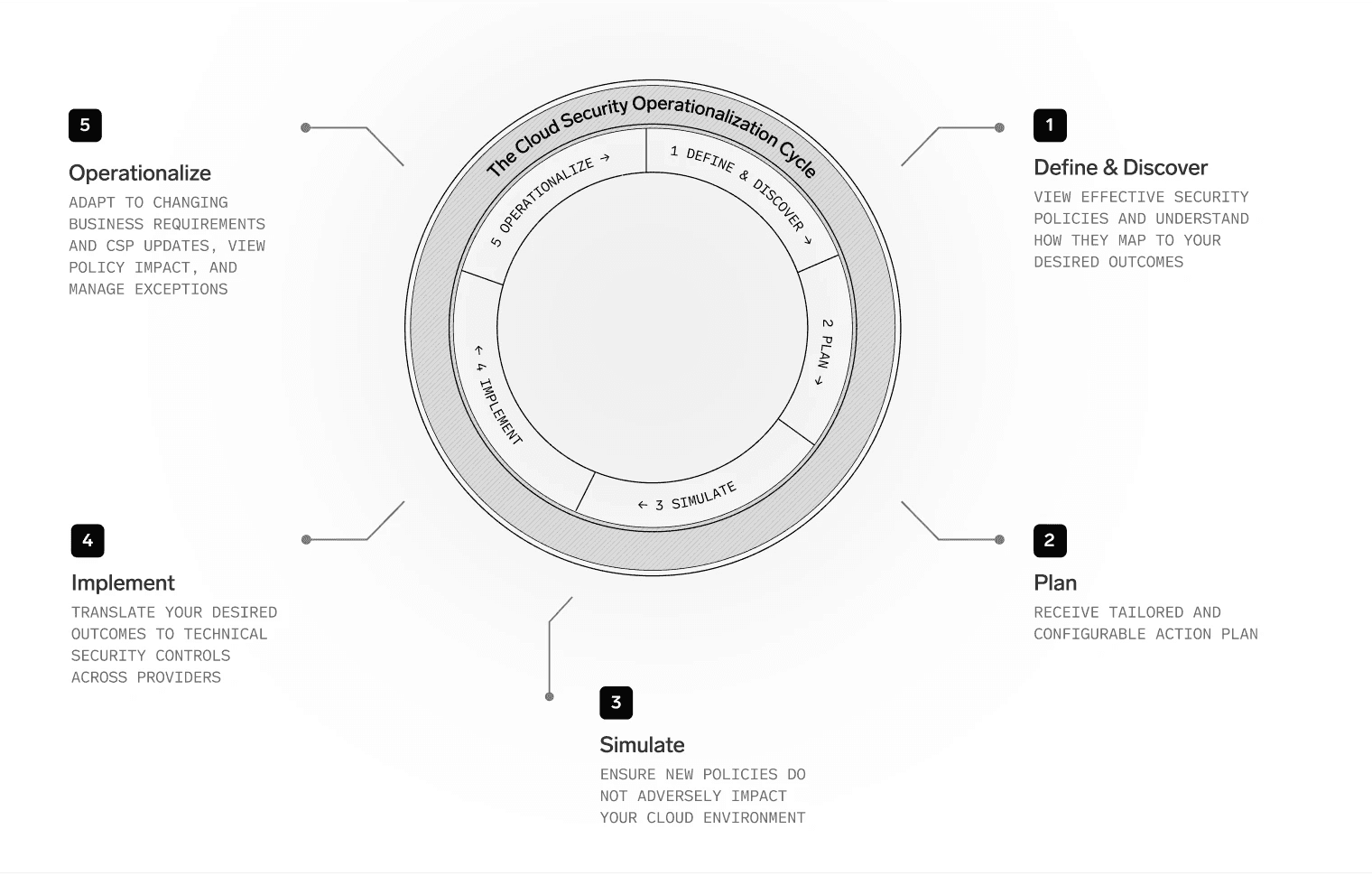
First, once you complete one outcome, you move on to the next.
Second, policies are living things. Cloud environments change daily. Teams refactor. New services are adopted. Providers introduce new features that create new paths, or new (and potentially better) ways to solve the same problem.
So you’re never really “done.” You’re continuously steering architecture toward a set of outcomes. As you enforce more secure-by-design guardrails, the operational load adds up, which leaves less time and fewer resources for the next one.
What we Heard Repeatedly from Security Teams
Across conversations with organizations of different sizes and industries, a few themes kept coming up.
1) The security outcome is the only thing that matters.
Security teams care about principles such as safe AI adoption, perimeter protection, least privilege, blast-radius reduction. They do not care about reconstructing those principles from thousands of disconnected controls.
2) The hardest part is making change safe.
Many organizations know what they should enforce, but they can’t afford downtime or surprise breakages. Simulation, preview, and staged rollout need to be first-class capabilities.
3) Exceptions are inevitable, but unmanaged exceptions are dangerous.
Guardrails fail quietly when exceptions become untracked, unowned, or permanent. Teams want exceptions to be explicit and manageable at scale.
4) Multi-cloud amplifies everything.
The intent can be the same, but the implementation never is. Different providers expose different primitives, policy languages, and technical enforcement models.
What this means is that mature cloud security programs often have a clear security standard on paper, but it’s only partially and inconsistently implemented. These challenges also lead to errors. We’ve seen policies inadvertently not enforced everywhere, and controls that exist but aren’t actually effective. As a result, organizations remain exposed even when they believe they’re safe.
Why We Started Native (and What We’re Building)
Native started from a simple observation: secure-by-design is clearly where the industry is heading, and the only place to achieve it is at the source. Indeed, cloud providers are working hard to deliver the underlying capabilities, but most teams don’t have the time or specialized cloud engineering capacity to do the work those capabilities require.
So we built Native to be a force multiplier for the people doing this work every day: security engineers and cloud architects. Our goal isn’t to replace how teams operate, but to accelerate the secure-by-design cycle they already follow. We’re also taking a strong stance on how this should be done: using cloud providers’ own primitives, because that’s where durable enforcement actually lives.
If this resonates, or even if it doesn’t, we’d love to hear what you think. Native came directly from what we heard in conversations with cloud security teams, and staying in that dialogue helps us keep improving.
About Gal Ordo
Gal Ordo is the Chief Product Officer and Co-Founder of Native. Before co-founding the company, he led product management for AWS Security Hub — AWS's native CNAPP — serving tens of thousands of customers worldwide. Gal has spent his career at the intersection of cloud infrastructure and cybersecurity, and now brings that experience to building a platform that helps organizations stay secure-by-design across every cloud environment. He holds an MBA from the University of Chicago Booth School of Business. At Native, Gal translates security intent into operational, enforceable controls, with a focus on making cloud security teams as effective as top security architecture teams. He writes on cloud security product strategy, posture management, and the operational shift from detection to enforcement.
Continue reading

Security Architecture & Strategy
Jul 13, 2026
Zero trust for AI agents goes beyond identity verification. Learn how the framework has evolved from perimeter to identity to enforced action boundaries, and what that means for cloud security architecture.

Security Architecture & Strategy
Jul 15, 2026
Cyera finds your regulated data. Native turns each classification into an enforced perimeter across AWS, Azure, Google Cloud, and OCI. See how the integration works.
"/><stop offset="1" stop-color="rgba(255, 255, 255, 0.5)"/></linearGradient></defs><path d="M 0.119 6.571 C 0.261 6.559 0.4 6.579 0.539 6.623 C 0.67 6.667 0.801 6.715 0.932 6.759 C 1.13 6.823 1.342 6.891 1.522 6.952 C 1.734 7.019 1.911 7.132 2.037 7.341 C 2.126 7.489 2.242 7.609 2.368 7.717 C 2.436 7.773 2.497 7.845 2.555 7.918 C 2.656 8.042 2.749 8.17 2.846 8.298 C 2.976 8.467 3.026 8.663 3.037 8.88 C 3.037 8.942 2.987 9 2.925 9 L 0.154 9 C 0.069 9 0 8.93 0 8.845 L 0 6.722 C 0 6.65 0.048 6.578 0.119 6.571 Z M 0.014 0.525 C 0.066 0.557 0.114 0.581 0.154 0.614 C 0.284 0.706 0.431 0.765 0.585 0.801 C 0.81 0.856 1.028 0.94 1.231 1.051 C 1.343 1.111 1.453 1.183 1.532 1.275 C 1.633 1.395 1.748 1.484 1.885 1.543 C 2.007 1.6 2.112 1.692 2.216 1.784 C 2.313 1.868 2.41 1.948 2.514 2.021 C 2.651 2.117 2.788 2.213 2.91 2.333 C 3.029 2.449 3.166 2.534 3.302 2.614 C 3.511 2.734 3.716 2.871 3.9 3.039 C 3.993 3.123 4.069 3.227 4.156 3.319 C 4.299 3.48 4.44 3.64 4.558 3.828 C 4.641 3.965 4.756 4.069 4.871 4.173 C 5.062 4.346 5.224 4.541 5.336 4.79 C 5.408 4.951 5.48 5.111 5.562 5.267 C 5.624 5.384 5.688 5.5 5.764 5.608 C 5.908 5.812 6.034 6.025 6.127 6.261 C 6.246 6.554 6.383 6.842 6.498 7.139 C 6.609 7.427 6.736 7.704 6.869 7.985 C 6.919 8.089 6.952 8.205 6.984 8.317 C 7.027 8.458 7.067 8.602 7.106 8.746 C 7.128 8.827 7.16 8.907 7.164 8.999 L 7.156 8.995 L 4.907 8.995 C 4.897 8.967 4.882 8.935 4.871 8.903 C 4.842 8.822 4.817 8.742 4.789 8.658 C 4.63 8.213 4.364 7.857 4.047 7.544 C 3.889 7.392 3.752 7.218 3.641 7.027 C 3.612 6.979 3.579 6.93 3.547 6.879 C 3.437 6.709 3.289 6.568 3.116 6.466 C 2.954 6.369 2.81 6.248 2.687 6.105 C 2.59 5.993 2.486 5.885 2.385 5.776 C 2.216 5.596 2.025 5.46 1.798 5.388 C 1.633 5.332 1.465 5.255 1.291 5.183 C 0.899 5.027 0.51 4.862 0.118 4.706 C 0.083 4.692 0.048 4.678 0.014 4.662 Z M 9.061 0 C 9.146 0 9.214 0.069 9.214 0.155 C 9.214 3.055 9.201 5.996 9.201 8.894 L 9.201 8.942 C 9.201 8.95 9.198 8.954 9.19 8.969 L 9.19 8.971 C 9.192 8.972 9.191 8.974 9.189 8.974 L 8.409 8.974 C 8.333 8.974 8.268 8.919 8.256 8.844 C 8.248 8.799 8.242 8.755 8.238 8.71 C 8.223 8.581 8.22 8.449 8.195 8.325 C 8.173 8.194 8.14 8.065 8.097 7.94 C 8.01 7.69 7.916 7.441 7.817 7.195 C 7.757 7.034 7.711 6.867 7.68 6.697 C 7.631 6.439 7.544 6.189 7.421 5.956 C 7.335 5.79 7.264 5.617 7.209 5.439 C 7.102 5.115 6.965 4.802 6.798 4.505 C 6.683 4.297 6.554 4.1 6.439 3.896 C 6.323 3.694 6.209 3.491 6.097 3.287 C 6.025 3.154 5.96 3.014 5.881 2.882 C 5.802 2.754 5.715 2.629 5.629 2.505 C 5.539 2.377 5.442 2.253 5.359 2.121 C 5.23 1.916 5.238 1.741 5.238 1.595 L 5.238 0.154 C 5.238 0.069 5.306 0 5.391 0 Z M 13.432 7.895 C 13.39 7.895 13.356 7.86 13.356 7.817 L 13.356 2.648 C 13.356 2.606 13.39 2.571 13.432 2.571 L 14.031 2.571 C 14.073 2.571 14.108 2.606 14.108 2.648 L 14.108 3.806 C 14.133 3.708 14.163 3.616 14.197 3.528 C 14.342 3.163 14.56 2.887 14.85 2.701 C 15.14 2.508 15.507 2.412 15.949 2.412 L 15.989 2.412 C 16.655 2.412 17.147 2.621 17.463 3.04 C 17.786 3.458 17.948 4.063 17.948 4.854 L 17.948 7.817 C 17.948 7.86 17.914 7.895 17.871 7.895 L 17.074 7.895 C 17.032 7.894 16.998 7.86 16.998 7.817 L 16.998 4.654 C 16.998 4.243 16.882 3.914 16.651 3.668 C 16.42 3.415 16.104 3.289 15.701 3.289 C 15.286 3.289 14.949 3.419 14.692 3.678 C 14.434 3.937 14.306 4.282 14.306 4.715 L 14.306 7.817 C 14.306 7.86 14.271 7.895 14.229 7.895 Z M 22.312 7.895 C 22.269 7.895 22.235 7.86 22.235 7.817 L 22.235 6.84 C 22.189 6.993 22.13 7.132 22.057 7.257 C 21.912 7.509 21.707 7.702 21.443 7.835 C 21.186 7.968 20.872 8.034 20.503 8.034 C 20.107 8.034 19.764 7.968 19.474 7.835 C 19.2 7.704 18.969 7.496 18.81 7.237 C 18.658 6.978 18.583 6.665 18.583 6.3 C 18.583 5.921 18.665 5.605 18.83 5.353 C 19.002 5.1 19.249 4.911 19.572 4.784 C 19.896 4.652 20.285 4.585 20.74 4.585 L 22.077 4.585 L 22.077 4.455 C 22.077 4.09 21.981 3.814 21.789 3.628 C 21.605 3.442 21.331 3.349 20.968 3.349 C 20.763 3.349 20.552 3.352 20.334 3.359 C 20.117 3.365 19.909 3.372 19.711 3.379 C 19.567 3.383 19.424 3.391 19.28 3.401 C 19.259 3.403 19.237 3.396 19.221 3.381 C 19.206 3.366 19.197 3.345 19.196 3.324 L 19.196 2.642 C 19.196 2.602 19.227 2.568 19.266 2.565 C 19.39 2.555 19.518 2.547 19.652 2.541 C 19.817 2.528 19.985 2.522 20.156 2.522 C 20.328 2.515 20.493 2.511 20.651 2.511 C 21.192 2.511 21.634 2.578 21.978 2.711 C 22.321 2.837 22.575 3.046 22.74 3.339 C 22.905 3.631 22.987 4.027 22.987 4.525 L 22.987 7.817 C 22.987 7.86 22.953 7.895 22.91 7.895 Z M 20.701 5.303 C 20.318 5.303 20.024 5.396 19.82 5.582 C 19.615 5.768 19.513 6.007 19.513 6.3 C 19.513 6.592 19.615 6.828 19.82 7.007 C 20.024 7.187 20.318 7.277 20.701 7.277 C 20.925 7.277 21.14 7.237 21.344 7.157 C 21.549 7.07 21.725 6.924 21.849 6.738 C 21.955 6.586 22.024 6.392 22.057 6.154 C 22.059 6.137 22.066 6.122 22.077 6.11 L 22.077 5.303 Z M 26.295 7.954 C 25.899 7.954 25.556 7.898 25.266 7.785 C 24.985 7.675 24.751 7.471 24.602 7.207 C 24.45 6.928 24.375 6.552 24.375 6.08 L 24.375 3.289 L 23.541 3.289 L 23.541 3.289 C 23.499 3.289 23.464 3.254 23.464 3.212 L 23.464 2.648 C 23.464 2.606 23.498 2.571 23.541 2.571 L 24.375 2.571 L 24.375 1.033 C 24.375 0.99 24.409 0.956 24.451 0.956 L 25.208 0.956 C 25.251 0.956 25.286 0.99 25.286 1.033 L 25.286 2.571 L 26.953 2.571 C 26.995 2.571 27.03 2.606 27.03 2.648 L 27.03 3.212 C 27.03 3.254 26.995 3.289 26.953 3.289 L 25.286 3.289 L 25.286 6.199 C 25.286 6.485 25.361 6.708 25.513 6.867 C 25.671 7.021 25.893 7.097 26.176 7.097 L 27.03 7.097 C 27.072 7.097 27.107 7.131 27.107 7.174 L 27.107 7.877 C 27.107 7.919 27.072 7.954 27.03 7.954 L 26.295 7.954 Z M 28.29 7.895 C 28.247 7.895 28.213 7.86 28.213 7.817 L 28.213 3.274 L 27.422 3.274 C 27.379 3.274 27.345 3.239 27.345 3.196 L 27.345 2.633 C 27.345 2.591 27.379 2.556 27.421 2.556 L 28.99 2.556 C 29.007 2.556 29.023 2.561 29.035 2.571 L 29.086 2.571 C 29.129 2.571 29.163 2.606 29.163 2.648 L 29.163 7.818 C 29.163 7.86 29.129 7.895 29.086 7.895 L 28.289 7.895 Z M 31.689 7.895 C 31.656 7.895 31.627 7.873 31.616 7.842 L 29.866 2.674 C 29.858 2.65 29.862 2.624 29.877 2.604 C 29.891 2.584 29.914 2.572 29.939 2.572 L 30.766 2.572 C 30.799 2.572 30.829 2.593 30.839 2.624 L 32.333 7.137 L 32.545 7.137 L 33.845 2.627 C 33.854 2.594 33.884 2.571 33.918 2.571 L 34.688 2.571 C 34.74 2.571 34.776 2.621 34.762 2.67 L 33.243 7.839 C 33.234 7.872 33.204 7.894 33.17 7.894 L 32.95 7.894 C 32.947 7.895 32.945 7.895 32.942 7.895 L 32.488 7.895 C 32.484 7.895 32.481 7.895 32.477 7.895 L 31.688 7.895 Z M 37.536 8.074 C 37.074 8.074 36.674 7.994 36.338 7.835 C 36.001 7.675 35.728 7.466 35.516 7.207 C 35.306 6.943 35.145 6.642 35.041 6.319 C 34.943 5.997 34.893 5.661 34.893 5.323 L 34.893 5.143 C 34.893 4.797 34.942 4.462 35.041 4.136 C 35.144 3.817 35.305 3.519 35.516 3.259 C 35.732 2.99 36.006 2.775 36.318 2.631 C 36.648 2.472 37.034 2.392 37.476 2.392 C 38.05 2.392 38.522 2.518 38.892 2.771 C 39.268 3.017 39.545 3.335 39.723 3.728 C 39.908 4.12 40.002 4.549 40 4.984 L 40 5.335 C 40 5.355 39.992 5.375 39.978 5.39 C 39.963 5.404 39.944 5.412 39.923 5.412 L 35.808 5.412 C 35.824 5.72 35.882 6.003 35.982 6.26 C 36.1 6.55 36.299 6.799 36.556 6.978 C 36.813 7.15 37.14 7.237 37.536 7.237 C 37.951 7.237 38.288 7.144 38.545 6.957 C 38.787 6.787 38.941 6.591 39.005 6.37 C 39.015 6.335 39.046 6.31 39.082 6.31 L 39.817 6.31 C 39.866 6.31 39.902 6.354 39.891 6.402 C 39.82 6.715 39.677 7.008 39.476 7.257 C 39.255 7.524 38.973 7.733 38.654 7.865 C 38.324 8.004 37.951 8.074 37.536 8.074 Z M 38.911 4.107 C 38.793 3.827 38.615 3.611 38.377 3.458 C 38.139 3.305 37.839 3.229 37.476 3.229 C 37.1 3.229 36.787 3.316 36.536 3.488 C 36.292 3.661 36.107 3.897 35.982 4.196 C 35.921 4.35 35.875 4.516 35.846 4.695 L 39.066 4.695 C 39.039 4.477 38.987 4.281 38.911 4.107 Z M 28.162 0.935 C 28.177 0.92 28.197 0.912 28.217 0.912 L 29.09 0.912 L 29.09 1.824 C 29.09 1.867 29.056 1.902 29.013 1.902 L 28.217 1.902 C 28.175 1.902 28.14 1.867 28.14 1.825 L 28.14 0.989 C 28.14 0.969 28.148 0.949 28.162 0.935 Z" fill="url(%23tzB6HfK_E-1335233321-linear-gradient)" height="8.999999828525105px" id="tzB6HfK_E" transform="translate(0 3)" width="40.00000175254525px"/></svg>)
" width="40.00000175254526px"><path d="M 0.119 6.571 C 0.261 6.559 0.4 6.579 0.539 6.623 C 0.67 6.667 0.801 6.715 0.932 6.759 C 1.13 6.823 1.342 6.891 1.522 6.952 C 1.734 7.019 1.911 7.132 2.037 7.341 C 2.126 7.489 2.242 7.609 2.368 7.717 C 2.436 7.773 2.497 7.845 2.555 7.918 C 2.656 8.042 2.749 8.17 2.846 8.298 C 2.976 8.467 3.026 8.663 3.037 8.88 C 3.037 8.942 2.987 9 2.925 9 L 0.154 9 C 0.069 9 0 8.93 0 8.845 L 0 6.722 C 0 6.65 0.048 6.578 0.119 6.571 Z M 0.014 0.525 C 0.066 0.557 0.114 0.581 0.154 0.614 C 0.284 0.706 0.431 0.765 0.585 0.801 C 0.81 0.856 1.028 0.94 1.231 1.051 C 1.343 1.111 1.453 1.183 1.532 1.275 C 1.633 1.395 1.748 1.484 1.885 1.543 C 2.007 1.6 2.112 1.692 2.216 1.784 C 2.313 1.868 2.41 1.948 2.514 2.021 C 2.651 2.117 2.788 2.213 2.91 2.333 C 3.029 2.449 3.166 2.534 3.302 2.614 C 3.511 2.734 3.716 2.871 3.9 3.039 C 3.993 3.123 4.069 3.227 4.156 3.319 C 4.299 3.48 4.44 3.64 4.558 3.828 C 4.641 3.965 4.756 4.069 4.871 4.173 C 5.062 4.346 5.224 4.541 5.336 4.79 C 5.408 4.951 5.48 5.111 5.562 5.267 C 5.624 5.384 5.688 5.5 5.764 5.608 C 5.908 5.812 6.034 6.025 6.127 6.261 C 6.246 6.554 6.383 6.842 6.498 7.139 C 6.609 7.427 6.736 7.704 6.869 7.985 C 6.919 8.089 6.952 8.205 6.984 8.317 C 7.027 8.458 7.067 8.602 7.106 8.746 C 7.128 8.827 7.16 8.907 7.164 8.999 L 7.156 8.995 L 4.907 8.995 C 4.897 8.967 4.882 8.935 4.871 8.903 C 4.842 8.822 4.817 8.742 4.789 8.658 C 4.63 8.213 4.364 7.857 4.047 7.544 C 3.889 7.392 3.752 7.218 3.641 7.027 C 3.612 6.979 3.579 6.93 3.547 6.879 C 3.437 6.709 3.289 6.568 3.116 6.466 C 2.954 6.369 2.81 6.248 2.687 6.105 C 2.59 5.993 2.486 5.885 2.385 5.776 C 2.216 5.596 2.025 5.46 1.798 5.388 C 1.633 5.332 1.465 5.255 1.291 5.183 C 0.899 5.027 0.51 4.862 0.118 4.706 C 0.083 4.692 0.048 4.678 0.014 4.662 L 0.014 0.525 Z M 9.061 0 C 9.146 0 9.214 0.069 9.214 0.155 C 9.214 3.055 9.201 5.996 9.201 8.894 L 9.201 8.942 C 9.201 8.95 9.198 8.954 9.19 8.969 L 9.19 8.971 C 9.192 8.972 9.191 8.974 9.189 8.974 L 8.409 8.974 C 8.333 8.974 8.268 8.919 8.256 8.844 C 8.248 8.799 8.242 8.755 8.238 8.71 C 8.223 8.581 8.22 8.449 8.195 8.325 C 8.173 8.194 8.14 8.065 8.097 7.94 C 8.01 7.69 7.916 7.441 7.817 7.195 C 7.757 7.034 7.711 6.867 7.68 6.697 C 7.631 6.439 7.544 6.189 7.421 5.956 C 7.335 5.79 7.264 5.617 7.209 5.439 C 7.102 5.115 6.965 4.802 6.798 4.505 C 6.683 4.297 6.554 4.1 6.439 3.896 C 6.323 3.694 6.209 3.491 6.097 3.287 C 6.025 3.154 5.96 3.014 5.881 2.882 C 5.802 2.754 5.715 2.629 5.629 2.505 C 5.539 2.377 5.442 2.253 5.359 2.121 C 5.23 1.916 5.238 1.741 5.238 1.595 L 5.238 0.154 C 5.238 0.069 5.306 0 5.391 0 L 9.06 0 Z M 13.432 7.895 C 13.39 7.895 13.356 7.86 13.356 7.817 L 13.356 2.648 C 13.356 2.606 13.39 2.571 13.432 2.571 L 14.031 2.571 C 14.073 2.571 14.108 2.606 14.108 2.648 L 14.108 4.794 C 14.108 4.827 14.081 4.854 14.048 4.854 C 14.033 4.854 14.018 4.848 14.007 4.836 C 13.995 4.825 13.989 4.81 13.989 4.794 C 13.994 4.296 14.064 3.873 14.197 3.528 C 14.342 3.163 14.56 2.887 14.85 2.701 C 15.14 2.508 15.507 2.412 15.949 2.412 L 15.989 2.412 C 16.655 2.412 17.147 2.621 17.463 3.04 C 17.786 3.458 17.948 4.063 17.948 4.854 L 17.948 7.817 C 17.948 7.86 17.914 7.895 17.871 7.895 L 17.074 7.895 C 17.032 7.894 16.998 7.86 16.998 7.817 L 16.998 4.654 C 16.998 4.243 16.882 3.914 16.651 3.668 C 16.42 3.415 16.104 3.289 15.701 3.289 C 15.286 3.289 14.949 3.419 14.692 3.678 C 14.434 3.937 14.306 4.282 14.306 4.715 L 14.306 7.817 C 14.306 7.86 14.271 7.895 14.229 7.895 Z M 22.312 7.895 C 22.269 7.895 22.235 7.86 22.235 7.817 L 22.235 6.377 C 22.235 6.334 22.2 6.3 22.158 6.3 L 22.153 6.3 C 22.111 6.3 22.077 6.265 22.077 6.222 L 22.077 4.455 C 22.077 4.09 21.981 3.814 21.789 3.628 C 21.605 3.442 21.331 3.349 20.968 3.349 C 20.763 3.349 20.552 3.352 20.334 3.359 C 20.117 3.365 19.909 3.372 19.711 3.379 C 19.567 3.383 19.424 3.391 19.28 3.401 C 19.259 3.403 19.237 3.396 19.221 3.381 C 19.206 3.366 19.197 3.345 19.196 3.324 L 19.196 2.642 C 19.196 2.602 19.227 2.568 19.266 2.565 C 19.39 2.555 19.518 2.547 19.652 2.541 C 19.817 2.528 19.985 2.522 20.156 2.522 C 20.328 2.515 20.493 2.511 20.651 2.511 C 21.192 2.511 21.634 2.578 21.978 2.711 C 22.321 2.837 22.575 3.046 22.74 3.339 C 22.905 3.631 22.987 4.027 22.987 4.525 L 22.987 7.817 C 22.987 7.86 22.953 7.895 22.91 7.895 Z M 20.503 8.034 C 20.107 8.034 19.764 7.968 19.474 7.835 C 19.2 7.704 18.969 7.496 18.81 7.237 C 18.658 6.978 18.583 6.665 18.583 6.3 C 18.583 5.921 18.665 5.605 18.83 5.353 C 19.002 5.1 19.249 4.911 19.572 4.784 C 19.896 4.652 20.285 4.585 20.74 4.585 L 22.099 4.585 C 22.141 4.585 22.175 4.619 22.175 4.663 L 22.175 5.225 C 22.175 5.268 22.141 5.303 22.099 5.303 L 20.701 5.303 C 20.318 5.303 20.024 5.396 19.82 5.582 C 19.615 5.768 19.513 6.007 19.513 6.3 C 19.513 6.592 19.615 6.828 19.82 7.007 C 20.024 7.187 20.318 7.277 20.701 7.277 C 20.925 7.277 21.14 7.237 21.344 7.157 C 21.549 7.07 21.725 6.924 21.849 6.738 C 21.955 6.586 22.024 6.392 22.057 6.154 C 22.067 6.08 22.166 6.052 22.208 6.114 L 22.318 6.277 C 22.328 6.291 22.333 6.31 22.332 6.327 C 22.296 6.694 22.205 7.004 22.057 7.257 C 21.912 7.509 21.707 7.702 21.443 7.835 C 21.186 7.968 20.872 8.034 20.503 8.034 Z M 26.295 7.954 C 25.899 7.954 25.556 7.898 25.266 7.785 C 24.985 7.675 24.751 7.471 24.602 7.207 C 24.45 6.928 24.375 6.552 24.375 6.08 L 24.375 1.033 C 24.375 0.99 24.409 0.956 24.451 0.956 L 25.208 0.956 C 25.251 0.956 25.286 0.99 25.286 1.033 L 25.286 6.199 C 25.286 6.485 25.361 6.708 25.513 6.867 C 25.671 7.021 25.893 7.097 26.176 7.097 L 27.03 7.097 C 27.072 7.097 27.107 7.131 27.107 7.174 L 27.107 7.877 C 27.107 7.919 27.072 7.954 27.03 7.954 L 26.295 7.954 Z M 23.541 3.289 C 23.499 3.289 23.464 3.254 23.464 3.212 L 23.464 2.648 C 23.464 2.606 23.498 2.571 23.541 2.571 L 26.953 2.571 C 26.995 2.571 27.03 2.606 27.03 2.648 L 27.03 3.212 C 27.03 3.254 26.995 3.289 26.953 3.289 L 23.541 3.289 Z M 28.29 7.895 C 28.247 7.895 28.213 7.86 28.213 7.817 L 28.213 2.648 C 28.213 2.606 28.247 2.571 28.29 2.571 L 29.086 2.571 C 29.129 2.571 29.163 2.606 29.163 2.648 L 29.163 7.818 C 29.163 7.86 29.129 7.895 29.086 7.895 L 28.289 7.895 Z M 31.689 7.895 C 31.656 7.895 31.627 7.873 31.616 7.842 L 29.866 2.674 C 29.858 2.65 29.862 2.624 29.877 2.604 C 29.891 2.584 29.914 2.572 29.939 2.572 L 30.766 2.572 C 30.799 2.572 30.829 2.593 30.839 2.624 L 32.55 7.793 C 32.558 7.817 32.554 7.843 32.539 7.863 C 32.525 7.883 32.502 7.895 32.477 7.895 L 31.688 7.895 Z M 31.948 7.895 C 31.905 7.895 31.871 7.86 31.871 7.817 L 31.871 7.214 C 31.871 7.172 31.906 7.137 31.948 7.137 L 32.942 7.137 C 32.985 7.137 33.019 7.172 33.019 7.214 L 33.019 7.817 C 33.019 7.86 32.985 7.895 32.942 7.895 L 31.948 7.895 Z M 32.429 7.895 C 32.405 7.895 32.382 7.883 32.367 7.864 C 32.353 7.844 32.348 7.819 32.355 7.796 L 33.845 2.627 C 33.854 2.594 33.884 2.571 33.918 2.571 L 34.688 2.571 C 34.74 2.571 34.776 2.621 34.762 2.67 L 33.243 7.839 C 33.234 7.872 33.204 7.894 33.17 7.894 L 32.429 7.894 Z M 37.536 8.074 C 37.074 8.074 36.674 7.994 36.338 7.835 C 36.001 7.675 35.728 7.466 35.516 7.207 C 35.306 6.943 35.145 6.642 35.041 6.319 C 34.943 5.997 34.893 5.661 34.893 5.323 L 34.893 5.143 C 34.893 4.797 34.942 4.462 35.041 4.136 C 35.144 3.817 35.305 3.519 35.516 3.259 C 35.732 2.99 36.006 2.775 36.318 2.631 C 36.648 2.472 37.034 2.392 37.476 2.392 C 38.05 2.392 38.522 2.518 38.892 2.771 C 39.268 3.017 39.545 3.335 39.723 3.728 C 39.908 4.12 40.002 4.549 40 4.984 L 40 5.335 C 40 5.355 39.992 5.375 39.978 5.39 C 39.963 5.404 39.944 5.412 39.923 5.412 L 35.385 5.412 C 35.343 5.412 35.309 5.378 35.309 5.335 L 35.309 4.772 C 35.309 4.729 35.343 4.695 35.385 4.695 L 39.176 4.695 C 39.235 4.695 39.272 4.758 39.243 4.81 L 39.233 4.827 C 39.194 4.896 39.084 4.868 39.077 4.789 C 39.053 4.533 38.998 4.306 38.911 4.107 C 38.793 3.827 38.615 3.611 38.377 3.458 C 38.139 3.305 37.839 3.229 37.476 3.229 C 37.1 3.229 36.787 3.316 36.536 3.488 C 36.292 3.661 36.107 3.897 35.982 4.196 C 35.863 4.495 35.804 4.841 35.804 5.233 C 35.804 5.612 35.863 5.954 35.982 6.26 C 36.1 6.55 36.299 6.799 36.556 6.978 C 36.813 7.15 37.14 7.237 37.536 7.237 C 37.951 7.237 38.288 7.144 38.545 6.957 C 38.787 6.787 38.941 6.591 39.005 6.37 C 39.015 6.335 39.046 6.31 39.082 6.31 L 39.817 6.31 C 39.866 6.31 39.902 6.354 39.891 6.402 C 39.82 6.715 39.677 7.008 39.476 7.257 C 39.255 7.524 38.973 7.733 38.654 7.865 C 38.324 8.004 37.951 8.074 37.536 8.074 Z" fill="rgb(250, 250, 250)" height="8.999999828525103px" id="ytRfC9Fgn" width="40.00000175254526px"/><path d="M 0 1.721 L 0 2.284 C 0 2.327 0.034 2.362 0.077 2.362 L 1.645 2.362 C 1.687 2.362 1.721 2.327 1.721 2.284 L 1.721 1.721 C 1.721 1.678 1.687 1.644 1.645 1.644 L 0.076 1.644 C 0.034 1.644 0 1.679 0 1.721 Z M 0.795 0.077 L 0.795 0.913 C 0.795 0.955 0.83 0.99 0.872 0.99 L 1.669 0.99 C 1.711 0.99 1.745 0.955 1.745 0.912 L 1.745 0 L 0.872 0 C 0.852 0 0.832 0.008 0.818 0.023 C 0.803 0.037 0.795 0.057 0.795 0.077 Z" fill="rgb(250, 250, 250)" height="2.3617210524480243px" id="oWKKSCytl" transform="translate(27.345 0.912)" width="1.7453642791111128px"/></g></svg>)



